Premise
Overview
This technical project is designed to evaluate your technical skills, creativity, and problem-solving abilities in both Data Engineering and Artificial Intelligence. The project will help us assess how well you understand the concepts and tools you’ll be working with during the internship. The project should take no more than 2 to 3 hours to complete.
Project Description
You are tasked with designing a simple data pipeline using Microsoft Fabric and performing data science
tasks using Python. Most likely, you don’t have experience with Microsoft Fabric. We’re interested in how
your mind works when you have to face a challenge like this. Microsoft Fabric is a comprehensive data
analytics platform that integrates data engineering, data science, data warehousing, and business
intelligence in one environment. By using Microsoft Fabric, we expect our interns to gain hands-on
experience with a tool that Microsoft expects to be widely adopted in the industry. This exposure not only
makes you more competitive in the job market but also prepares you for real-world scenarios where you
are likely to encounter similar integrated platforms.
Microsoft Fabric is a paid tool, so in order to solve these exercises, you have to simply read the
documentation to have an introduction to the tool, watch a few tutorials if needed and answer the
questions based on your findings and your prior knowledge from University courses. You don’t need to
access Fabric for this basic assignment. You don’t have to implement the solution, only to design it based
on the documentation that you read. You can use text descriptions or any type of visual representation to
answer the questions (e.g. Dataflow diagrams) for Section 1. For Section 2 you can implement the solution
for free using Google Colab or any other local python environment.
The project is divided into two main sections: Data Engineering and Artificial Intelligence.
Section 1
Scenario
You are a new data engineer at a retail company. The company has a dataset containing information on
customer transactions. Your task is to design and implement a data pipeline that ingests, processes, and
stores this data using Microsoft Fabric.
The dataset is available here: https://www.kaggle.com/datasets/fahadrehman07/retail-transaction-dataset?resource=download
Task 1 premise
Question: First, you have to bring this data into Fabric. How do you envision this? What will be the expected steps? How exactly will it be stored? Is the data in a suitable format and size to ingest in Fabric? What can you do related to storage in order to improve the performance of the future data queries if the size of the dataset is expected to grow in time (hint: e.g. partition the data)? (Answer with text descriptions or diagrams)
Task 1 solution
Firstly, I will begin by looking at the data set given in the premise in order to get a feeling for what I am working with.
The data set is presented in csv format and has a size of around 13MB (important for later). It seems to be a retail transaction data set, basically offering you a peek at common consumer purchase patterns with the present columns being : CustomerId, ProductId, Quantity, Price, TransactionDate, PaymentMethod, StoreLocation, ProductCategory, AppliedDiscount and TotalAmount.
Since the data set is given in csv format which is compatible with the import feature of Microsoft Fabric and the size is not significant, the import should be pretty straight forward. We should plan for further expansion tho.
Okay, how how do I import it? Firstly, in what? A quick look around google later, the most obvious choice was between a Data Lake or a Data Warehouse. I would go with a Data Warehouse since it is meant for already structured data (exactly like my data set) while a Data Lake is more inclined towards raw data meant for analysis and further implications in various projects. Source.
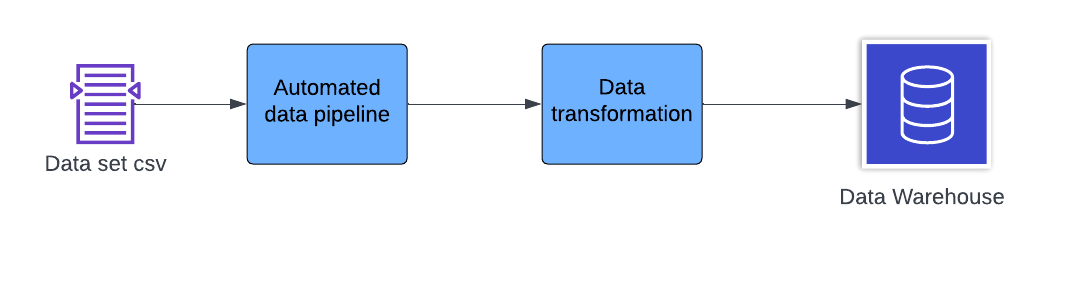
In order to import this data into Microsoft Fabric we could setup a pipeline. Pipeline setup:
- Configure an automated data pipeline within Microsoft Fabric.
- Source : We should point the pipeline towards the source location of the csv file.
- Transformation : We should always think about transforming data when we are doing an import in order to further suit our needs, for example remove unnecessary columns or filter just what we need.
- Destination : Finally, we set the pipeline to store the ingested data into our Data Warehouse, as explained earlier.
Source.
What can you do related to storage in order to improve the performance of the future data queries if the size of the dataset is expected to grow in time (hint: e.g. partition the data)?
Since the ingested data is stored in a Data Warehouse, it is prone to efficient querying. In order to further improve the performance, from my work experience, I would suggest partitioning the data by TransactionDate and possibly by ProductId. Additionally, converting the data into Parquet format will improve storage efficiency. Source.
Data flow diagram :
Task 2 premise
Question: Like most of the datasets you’ll find in your practice, this dataset has some data issues that
should be corrected. You need to find a way within Microsoft Fabric to perform the following
transformations:
Separate TransactionDate column in 2 distinct columns for Date and Time.
Aggregate the TotalAmount spent by each customer per month.
Replace the “Home Decor” values from the ProductCategory column with “Home Products”.
Create a new column HighValueCustomer that is a boolean column that assigns True or False based on
your own rule. Think about a rule with a logic that makes sense in the context.
Load the transformed data into a new table in your Data Lake.
How do you envision solving this based on your research on Microsoft Fabric? No implementation is
needed.
(Answer with text descriptions, images or diagrams).
Task 2 solution
Separate TransactionDate into 2 columns. As I explained previously, before sending the ingested data to the Data Warehouse we should parse it through a Data Transformation step. In order to achieve what is asked, there are Microsoft data pipeline capabilities that could get the expected result. Data pipelines in Fabric are designed to allow for complex data manipulations and transformations as part of the data flow. Within the pipeline, we could add a transformation step for the received data. Fabric allows for transformations through both low-code/no-code interfaces and SQL-based transformations and for this task, I think that a simple SQL snippet should suffice. Source.
SQL snippet :
SELECT
CustomerID,
ProductID,
Quantity,
Price,
CAST(TransactionDate AS DATE) AS Date,
CAST(TransactionDate AS TIME) AS Time,
etc.
FROM
RetailTransactions
Explanation : Casting the datetime variable as DATE and TIME respectively, we will only get the DATE and TIME part of the initial value.
Aggregate the TotalAmount spent by each customer per month. The first step would be separating the Year and the Month values from TransactionDate in order to differentiate between the entries. We should use a transformation step in the pipepline to create new entries just like we did last time.
SQL snippet :
SELECT
CustomerId,
YEAR(TransactionDate) AS Year,
MONTH(TransactionDate) AS Month,
TotalAmount
FROM
RetailTransactions
Now that we have extracted the relevant information, we could agregate the TotalAmount for each customer on a monthly basis.
Step 1 : Add an aggregation component to the pipeline.
Step 2 : Configure the aggregation component.
SQL snippet :
SELECT
CustomerId,
YEAR(TransactionDate) AS Year,
MONTH(TransactionDate) AS Month,
SUM(TotalAmount) AS TotalSpent
FROM
RetailTransactions
GROUP BY
CustomerId,
YEAR(TransactionDate),
MONTH(TransactionDate);
This basically just sums the TotalAmount based on each month.
As always, after getting the result we should do some data validation in order to make sure that we have consistency.
Replace the “Home Decor” values from the ProductCategory column with “Home Products”. This will be pretty straight forward since we could just use a case when statement. We should insert a transformation component in the pipeline with the directive of changing the values in ProductCategory just when the case is met.
SQL snippet :
CASE
WHEN ProductCategory = 'Home Decor' THEN 'Home Products'
ELSE ProductCategory
END AS ProductCategory
Create a new column HighValueCustomer that is a boolean column that assigns True or False based on your own rule. Think about a rule with a logic that makes sense in the context. The goal for this task is to create a HighValueCustomer column in my database. A simple rule I would personally think of would be that a customer who has spent more than 10k should be moved to the High Value Customer status. Using a data pipeline we could add a data transformation step in order to filter our customers based on our new created rule.
SQL snippet :
SELECT
CustomerId,
SUM(TotalAmount) AS TotalSpent
FROM
RetailTransactions
GROUP BY
CustomerId;
And in order to actually sort the data and filter for the sum greater than 10k we could do something like this :
SQL snippet :
CASE
WHEN TotalSpent > 10000 THEN 'True'
ELSE 'False'
END AS HighValueCustomer
Load the transformed data into a new table in your Data Lake. As I explained earlier, I would use a Data Warehouse but the process of transforming the data into a new table should be identical. Firstly, defining the table is crucial. The table should have the same fields i.e. CustomerId, Year and so on and if we are using a pipeline, the pipeline can include a step that automatically creates the table based on the schema defined by my transformed data.
Task 3 solution
Question: How will you use Microsoft Fabric to create a simple dashboard? After doing a little bit of research, the most obvious first step in creating this sort of dashboard should be sanitizing and validating the data. After you are sure that the data you are working with is indeed accurate we should exploit the fact that Microsoft Fabric integrates with Power BI. We could navigate to the Power BI section in Microsoft Fabric and simply choose Create and then Report. The next obvious step would be connecting this Report to the prepared dataset stored in our Data Warehouse. The final step is just using the Get Data feature in Power BI in order to ingest the stored data. Now all that is left to do is design an intuitive layout in order to display your findings. I also created a mock dashboard implementation.
A chart for total monthly sales by product category & a chart showing the number of HighValueCustomers over time.
Section 2
Task 1
Load the data you created into a Pandas DataFrame. Create new features such as the total amount spent in the last 3 months, the average transaction amount, and the number of distinct product categories purchased, etc. Create a target variable IsHighValueNextMonth which is True if the customer becomes a HighValueCustomer in the next month, otherwise False. Clean the dataset if needed.
Solution :
Let`s start by loading the csv data into a dataframe in order to see if it picks it up.
Code :
import pandas as pd
# Load phase
df = pd.read_csv('Retail_Transaction_Dataset.csv')
# Convert TransactionDate to datetime
df['TransactionDate'] = pd.to_datetime(df['TransactionDate'])
# Simple sort
df.sort_values(by=['CustomerID', 'TransactionDate'], inplace=True)
# Print check
print(df.head())
Code run :
06:03:38 archie@Archie randomPy → python3 ai.py
CustomerID ProductID Quantity Price TransactionDate PaymentMethod StoreLocation ProductCategory DiscountApplied(%) TotalAmount
81519 14 A 5 60.649721 2023-08-06 06:45:00 Credit Card Unit 3258 Box 4585\nDPO AE 23889 Books 15.504050 256.232791
80034 42 B 7 88.861581 2023-05-19 21:52:00 PayPal 565 Ashlee Lock\nStephaniefort, CA 33648 Home Decor 19.191090 502.656523
24358 49 A 1 25.152676 2023-06-05 13:10:00 Debit Card USCGC Anthony\nFPO AP 93458 Electronics 14.923377 21.399047
57189 59 B 4 37.424038 2023-08-19 03:50:00 Debit Card USCGC Carpenter\nFPO AE 70852 Clothing 6.736390 139.612036
86585 59 D 8 14.867200 2024-04-01 01:06:00 Debit Card 1854 Bailey Dam\nWest April, NC 97920 Home Decor 7.614866 109.880660
The next step should be implementing the new features. Since they are simple interogations and sorts it shouldn`t be very difficult.
Total spent in the last 3 months :
df['TotalSpentLast3Months'] = df.groupby('CustomerID').apply(
lambda x: x.set_index('TransactionDate').rolling('90D')['TotalAmount'].sum()
).reset_index(level=0, drop=True)
Average transaction amount :
df['AvgTransactionAmount'] = df.groupby('CustomerID')['TotalAmount'].expanding().mean().reset_index(level=0, drop=True)
Number of distinct categories :
distinct_categories = []
categories_set = set()
for category in df['ProductCategory']:
categories_set.add(category)
distinct_categories.append(len(categories_set))
df['DistinctCategories'] = distinct_categories
Now, we should create a target variable IsHighValueNextMonth which is true if the customer will become high value in the next month.
Firstly, let`s create the IsHighValueNextMonth column based on the threshold :
high_value_threshold = 10000
monthly_spending['IsHighValueCustomer'] = monthly_spending['TotalAmount'] > high_value_threshold
We need to shift the column in order to create the target variable :
monthly_spending['IsHighValueNextMonth'] = monthly_spending.groupby('CustomerID')['IsHighValueCustomer'].shift(-1)
Now all that is left to do is merge back into the original dataframe, sanitize the data and check our code for errors.
df = pd.merge(df, monthly_spending[['CustomerID', 'YearMonth', 'IsHighValueNextMonth']],
how='left', on=['CustomerID', 'YearMonth'])
df['IsHighValueNextMonth'] = df['IsHighValueNextMonth'].fillna(False)
df.dropna(inplace=True)
Code run :
CustomerID TransactionDate TotalAmount IsHighValueNextMonth
0 14 2023-08-06 06:45:00 256.232791 False
1 42 2023-05-19 21:52:00 502.656523 False
2 49 2023-06-05 13:10:00 21.399047 False
3 59 2023-08-19 03:50:00 139.612036 False
4 59 2024-04-01 01:06:00 109.880660 False
5 65 2023-06-18 10:29:00 548.006625 False
6 87 2023-08-21 15:23:00 41.515905 False
7 96 2024-04-06 12:35:00 194.356816 False
8 98 2023-12-20 11:49:00 166.934647 False
9 100 2023-05-13 17:17:00 710.062576 False
Task 2
Split the data into training and testing sets.
Train a simple model of your choice (e.g., Logistic Regression or Decision Tree) to predict
IsHighValueNextMonth.
Evaluate the model using appropriate metrics such as accuracy, precision, and recall.
Let`s break down the implementation step by step. Firstly I loaded the data and only used a small batch since otherwise the process would be killed for intense operations.
df = pd.read_csv('Retail_Transaction_Dataset.csv')
df = df.sample(frac=0.1, random_state=42) # Use 10%
Then, I applied a datetime conversion in order to facilitate date-based operations.
df['TransactionDate'] = pd.to_datetime(df['TransactionDate'])
After the previous implementation of high value sort, we should prepare the data for modeling.
X = df.drop(columns=['IsHighValueNextMonth', 'CustomerID', 'TransactionDate', 'YearMonth'])
y = df['IsHighValueNextMonth']
encoder = OneHotEncoder(sparse_output=True, drop='first')
X_sparse = encoder.fit_transform(X)
The dataset is split into training and testing sets, with 70% of the data used for training and 30% for testing.
X_train, X_test, y_train, y_test = train_test_split(X_sparse, y, test_size=0.3, random_state=42)
A logistic regression model is initialized and trained using the training data.
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
Predictions are made on the testing set (X_test) using the trained logistic regression model.
y_pred = model.predict(X_test)
Then, the model is evaluated using accuracy, precision, and recall metrics, which are standard for classification tasks.
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
print(f'Precision: {precision:.2f}')
print(f'Recall: {recall:.2f}')
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
print("\nConfusion Matrix:")
print(conf_matrix)
print("\nClassification Report:")
print(class_report)
Task 3
Propose at least one creative feature that could improve the model’s performance. Implement this
feature and re-evaluate the model.
To improve the model’s performance, we can introduce a new feature that provides additional information about the customers' behavior. One such creative feature could be the Change in Spending Behavior over the past few months. This feature could capture whether a customer’s spending has increased, decreased, or remained stable, which might be a strong indicator of whether they will become a high-value customer in the next month.
In order to implement this, we should just calculate the change in spending behavior and then merge the data back into the original dataframe.
Code :
# Calculation
monthly_spending['PrevMonthSpending'] = monthly_spending.groupby('CustomerID')['TotalAmount'].shift(1)
monthly_spending['SpendingChange'] = (monthly_spending['TotalAmount'] - monthly_spending['PrevMonthSpending']) / monthly_spending['PrevMonthSpending']
monthly_spending['SpendingChange'].fillna(0, inplace=True) # Replace NaN values with 0 (e.g., for the first month)
# Merge
df = pd.merge(df, monthly_spending[['CustomerID', 'YearMonth', 'IsHighValueNextMonth', 'SpendingChange']],
how='left', on=['CustomerID', 'YearMonth'])
Suggest a potential business use case for the predictive model in a retail environment.
The predictive model can be used to identify customers who are likely to become high-value in the next month, allowing retailers to target these customers with personalized promotions and product recommendations. This strategy can boost customer engagement, increase sales, and improve overall customer retention.
Full code for this section :
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix, classification_report
from sklearn.preprocessing import OneHotEncoder
from scipy.sparse import csr_matrix
df = pd.read_csv('Retail_Transaction_Dataset.csv')
df = df.sample(frac=0.1, random_state=42)
df['TransactionDate'] = pd.to_datetime(df['TransactionDate'])
df.sort_values(by=['CustomerID', 'TransactionDate'], inplace=True)
df['YearMonth'] = df['TransactionDate'].dt.to_period('M')
monthly_spending = df.groupby(['CustomerID', 'YearMonth'])['TotalAmount'].sum().reset_index()
high_value_threshold = 100
monthly_spending['IsHighValueCustomer'] = monthly_spending['TotalAmount'] > high_value_threshold
monthly_spending['IsHighValueNextMonth'] = monthly_spending.groupby('CustomerID')['IsHighValueCustomer'].shift(-1)
monthly_spending['IsHighValueNextMonth'] = monthly_spending['IsHighValueNextMonth'].fillna(False)
monthly_spending['PrevMonthSpending'] = monthly_spending.groupby('CustomerID')['TotalAmount'].shift(1)
monthly_spending['SpendingChange'] = (monthly_spending['TotalAmount'] - monthly_spending['PrevMonthSpending']) / monthly_spending['PrevMonthSpending']
monthly_spending['SpendingChange'].fillna(0, inplace=True)
df = pd.merge(df, monthly_spending[['CustomerID', 'YearMonth', 'IsHighValueNextMonth', 'SpendingChange']],
how='left', on=['CustomerID', 'YearMonth'])
df.dropna(inplace=True)
X = df.drop(columns=['IsHighValueNextMonth', 'CustomerID', 'TransactionDate', 'YearMonth'])
y = df['IsHighValueNextMonth']
encoder = OneHotEncoder(sparse_output=True, drop='first')
X_sparse = encoder.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_sparse, y, test_size=0.3, random_state=42)
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
print(f'Precision: {precision:.2f}')
print(f'Recall: {recall:.2f}')
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
print("\nConfusion Matrix:")
print(conf_matrix)
print("\nClassification Report:")
print(class_report)